I was reading a New York Times article titled "Agency’s ’04 Rule Let Banks Pile Up New Debt". It is a pretty damning article on the SEC and describes a quiet decision made by them to allow investment banks to take on more debt than previously allowed under the assumption that the banks were able to manage their risk better with their newfangled computer models. This allowed Bear Stearns (R.I.P.) to raise it's leverage ratio to 33:1, which seems extraordinarily high. Anyway, while reading it I stumbled over this paragraph:
A lone dissenter — a software consultant and expert on risk management — weighed in from Indiana with a two-page letter to warn the commission that the move was a grave mistake. He never heard back from Washington.The software consultant was Leonard D. Bole, of Valparaiso, Ind. and he was expressing doubts that computer models could protect companies seeing that they had failed to do so in the collapse of a hedge-fund in 1998 and the market plunge in 1987. While I have my doubts that any computer model can calculate risk well enough and certainly increasing allowed leverage ratios seems just plain daft, I think the current credit crisis is now just down to trust. Or the lack of it.
So, if it is a trust problem, how would a computer scientist approach the problem? First of all, I need to point out that trust is really a human issue, so there is a limit to how much computers can help, just as I doubt we can model risk. However, one of the problems is that there is a certain degree of mortgages that are of too high risk, but banks don't know what their exact exposure is, let alone that of their competitors. The result is that no one trusts each other and the capital market has suffered a form of seizure or heart attack.
A couple of years I was leading a project exploring Data Centric Security and as a part of my research I looked into provenance. We never had time to weave it into the model properly, but identified it as an important aspect that eventually needed to be included. But, wait. What is provenance?
Take paper. Paper documents have great provenance. You fill out a form, hand it in. It gets handled, gets coffee stains over it, stapled to other documents, stamped, filed, refiled, etc. By examining a paper document you get a feeling for where that document has been and what it went through. That is provenance.
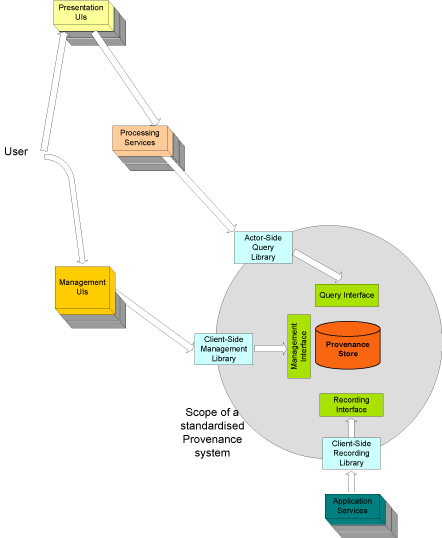
Unfortunately, electronic documents don't have provenance out of the box. Luckily, there has been some research into how provenance can be added. The project I was exposed to at IBM Research was the EU Provenance Project that was a part of the European Commission's Sixth Framework Programme, bless their cotton socks. Their proposed architecture, if I remember correctly, was to place hooks in document processing which record document use (CRUD operations: create, read, update, delete). Though I'm not sure if that is the way I would have done it, it certainly work work unless someone cheated or didn't implement the hooks, though I assume that would be uncovered the next time the provenance recording system saw the document.
How would provenance help in the credit crisis? If we just isolate the problem of sub-prime mortgages (and my brother, who knows much more about the financial industry assures me that there are a whole pile of other problems) it does look like a provenance problem to me. From my perspective as an outsider, what seemed to be happening was that these sub-prime mortgages were being sold, repackaged with other debt, sold again and so on. In the end, the last one in the chain didn't know what he/she was actually getting. The lack of provenance of these aggregate debt packages meant it wasn't possible to sufficiently well calculate what the risk was (in itself a dubious thing, but made even more difficult in this case.)
Remember that all financial instruments is really just a document of sorts that we attach a value to. The document has no intrinsic value. Take currency: The dollar bill has no real value. You can't eat it. It doesn't produce a lot of energy when burned. However, we place a certain amount of trust in it as the intricate design and the type of paper tells us that it comes from a trusted source: in this case the US Treasury. The provenance of this bill allows us to accept that the risk is low that the extrinsic value is not one dollar, US.
When aggregating debt from multiple sources you need to collect the provenance of all the included debt documents. This allows you to better estimate the risk associated with the aggregate debt and also find inconsistencies that I really really hope dont exist like circular provenance (which would be similar to a Ponzi scheme.) It also would allow the banks to identify the bad parts of the debts and calculate their exposure, which is something that they don't seem to be able to do at the moment. If they could, they would probably find that the bad debt they own is not as bad as it could be and there would be less uncertainty. Amongst other things, it is the uncertainty about the exposure to bad debt that has resulted in the credit crisis.
While not all the problems that banks are facing can be solved by computer scientists or mathematicians, and you can argue that we have been instrumental in getting us into this mess, provenance standards for financial documents would go a long way to alleviating the problems we have at the moment.




